The code is your specification, introducing cargo spec
Today, I want to introduce a tool called cargo-spec. We’ve been using it to specify kimchi, the general-purpose zero-knowledge proof system that is used in production for the Mina blockchain.
Before I introduce the tool, let me give some motivation behind why we created it, as well as why it is designed the way it is.
Specifications are important
First, let’s talk about specifications. Most of the cryptographic schemes that are used in the wild tend to be specified. This is not necessarily a crypto thing, but this is where I have experience. These specifications often look like RFCs, but it is not the only standard.
More importantly, specifications are multi-purpose. For example, they are used to help others implement an algorithm or protocol. This is usually the reason for these RFCs, but not necessarily what my tool targets.
Specifications are also used to help others understand how a protocol works. Indeed, if you want to understand a protocol, and it only exists as code, you’ll have to reverse engineer the code. Not everyone is good at reverse engineering. I would even argue that most people are bad at it. Not everyone can read the language you implemented your protocol in. Not everyone has the time to do it.
I used to work in a team where researchers wanted to formally analyze a protocol, but had no clue how it worked. And of course, they didn’t want to read the massive Rust codebase to do that. Security engineers would want to review it for bugs, but what is a bug without a spec? How can you understand the logic without a higher level document describing the protocol?
This is where specifications can also be really useful: to let security engineers audit your code. With a spec, they can simply match it to the code, and any divergence is a bug.
Your code is a book
I want to take a short detour to talk about writing. Writing code is like writing a book. It will be read again and again, changed, and maintained by others.
A book has sections, chapters, intros, outros, callouts, etc. Why shouldn’t code have the same things? Code sorts of has that already: files, modules, packages, namespaces, function names, variable names, comments, etc. are all tricks a developer can use to make their code readable.
But this doesn’t mean you can’t add actual sections in your code! There’s probably a reference to Knuth’s literal programming, but it’s a bit old, so I’ll give you a reference I really enjoyed recently: Literate Programming in the Large by Timothy Daly.
In this talk, Timothy makes the point that we’re the first user of our documentation: as we will all forget the code we wrote at some point, documentation (or a specification) might help drastically. Without it, changing the code could become a herculean task.
So Timothy’s point is that you should write a book about your code. That there’s no reason not to write and write and write. Perhaps there’ll be too much stuff? But we live in the future and we don’t look at real books, but at pages that you can grep and index. Even outdated stuff might help, as it will give some insight or rational.
How to specify?
Back to specs! The way I’ve worked in the past with specifications, was to write them as documents that lived outside of the codebase. But when you work on a project with a home-made protocol, you always have a reference implementation. That reference implementation is a living thing, it changes over time. This means that specifications of living projects tend to diverge from the implementation(s), unless they are maintained by rigorous developers.
The other solution is to write your specification in the code, where updates can be made by developers more easily as they adjust the code. But a specification is a structured document, with intros, outros, overviews, and other things that aren’t really a good fit for being split apart in multiple files.
One day, I asked myself the question, why not both?
This is where cargo-spec comes in.
Cargo-spec
cargo-spec is a tool written in Rust, although it works with codebases in any languages, to implement these ideas.
The tool expects two things:
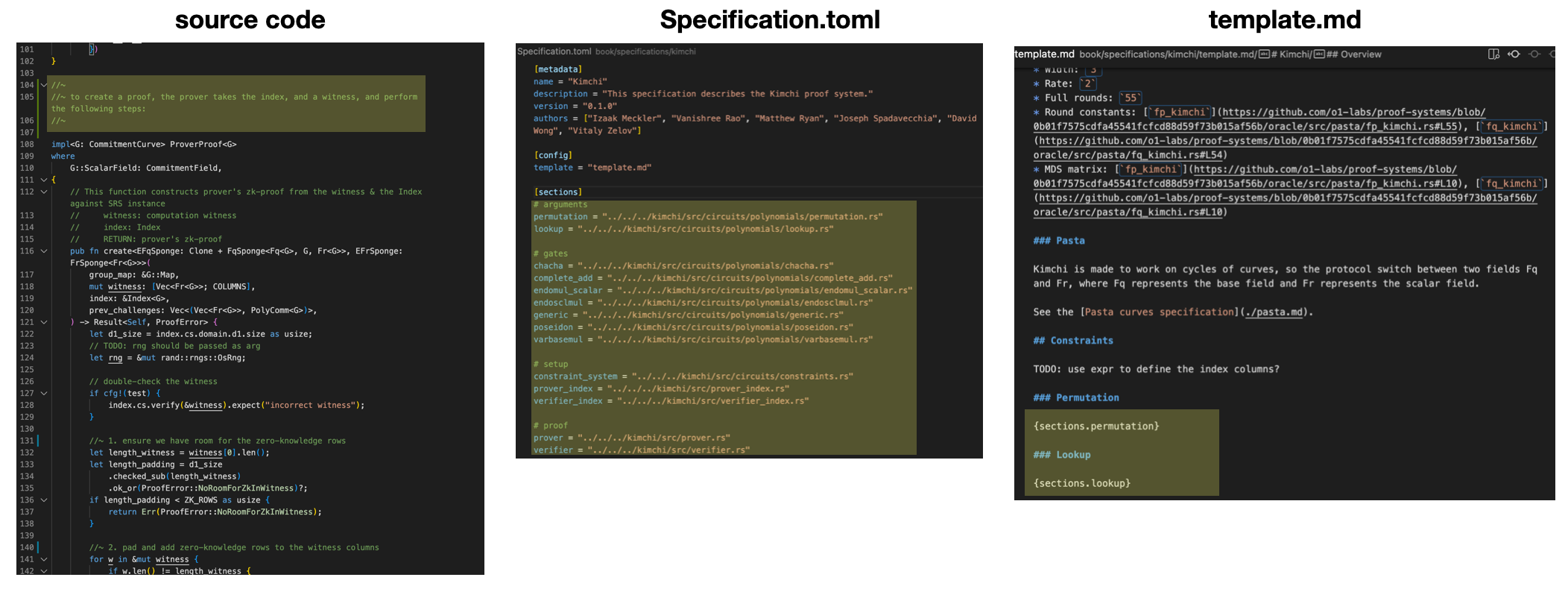
- a template, which contains the organization of your spec in markdown. You can write content there, but also use placeholders when you want parts to be filled by your code.
- a specification file, that helps you list the places in your code that you want to use in the specification.
The tool then extract parts of your code, replace the placeholders of your spec with that content, and produces the final specification (for now two formats are available: markdown and respec).
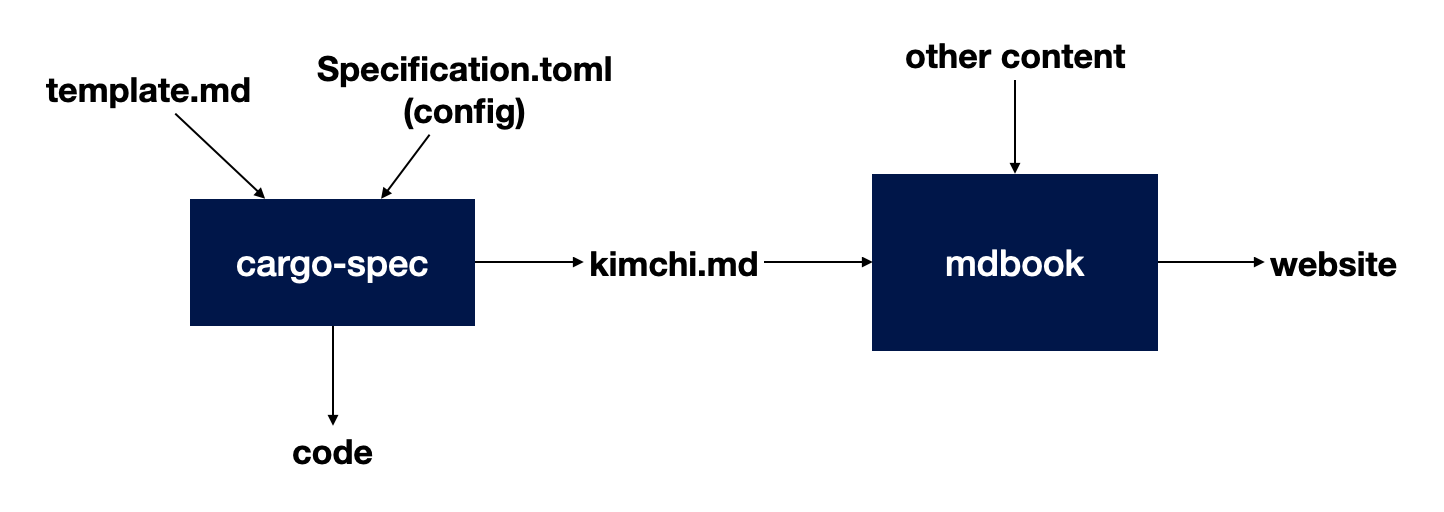
The diagram above shows how the kimchi specification is created. You can then use mdbook to serve it, as it contains LaTeX equations. We could have used hugo (which we did, initially), or really any other tool. You might also just want to have your spec in markdown file and leave it at that.
What is extracted from your code? Comments starting with a special prefix: //~ (or #~ in python, or (*~ ... *) in OCaml, etc.)
Rustdoc vs spec doc
You can ignore this section if you’re not interested in specifying Rust code, although I’ll give some insights that might be useful for other languages that also support special comments for code documentation.
By default, Rust has two types of comments: the normal ones (//), but also documentation comments (///, //!, and /** ... */). When you run cargo doc, the Rust documentation comments from your code get parsed and an HTML documentation is generated from them.
Since you can’t use both spec comments and doc comments, how can you reconcile the two? The philosophy of cargo-spec, is that a language doc comment should be used to specify the interface of the code only; not the internal logic. As such, documentation should treat its library like a blackbox. Because who uses documentation? Developers who want to work with the library without having to understand its inners.
On the other hand maintainers, contributors, reviewers, etc. will mostly look at what’s inside, and this is what you should specify using spec comments.
Examples
You’re curious to see it in action? Interestingly, The specification of cargo spec is written using cargo spec itself. It’s a pretty simple respec specification mostly here to showcase the tool.
During the last weeks we’ve been working on the Kimchi specification, which is written using cargo-spec as well. You can check it out here, but keep in mind that it is still work in progress.
We’re excited to see if this will change the game, and if it will push more people to specify their code. Let us know if you find it useful :)